What your coding assistant really does when you ask about your codebase
Different questions travel different paths through the same chat window. Knowing those paths changes how you ask.

You’re in your coding assistant. You ask, “Where is authentication handled?” Seconds later, the right files are open.
You ask, “Any other places we do retries like this?” It surfaces three similar patterns from across the repo.
You ask, “Find every function that writes to this variable.” It lists them.
Three different questions. Three quick, useful answers. All coming back through the same chat window, all feeling like the same tool doing the same thing.
Under the hood, they aren’t. Each of those questions likely travelled a different path to get to its answer. Different paths mean different strengths, different blind spots, and different moments where the precision of the answer depends on how the question was shaped. Worth understanding what those paths actually are.
The Structure Problem
Most of what’s written about retrieval assumes the corpus is prose. Support articles, policy documents, knowledge bases. These are flat. Paragraphs follow each other, headings are mostly decorative, and meaning lives in the words themselves.
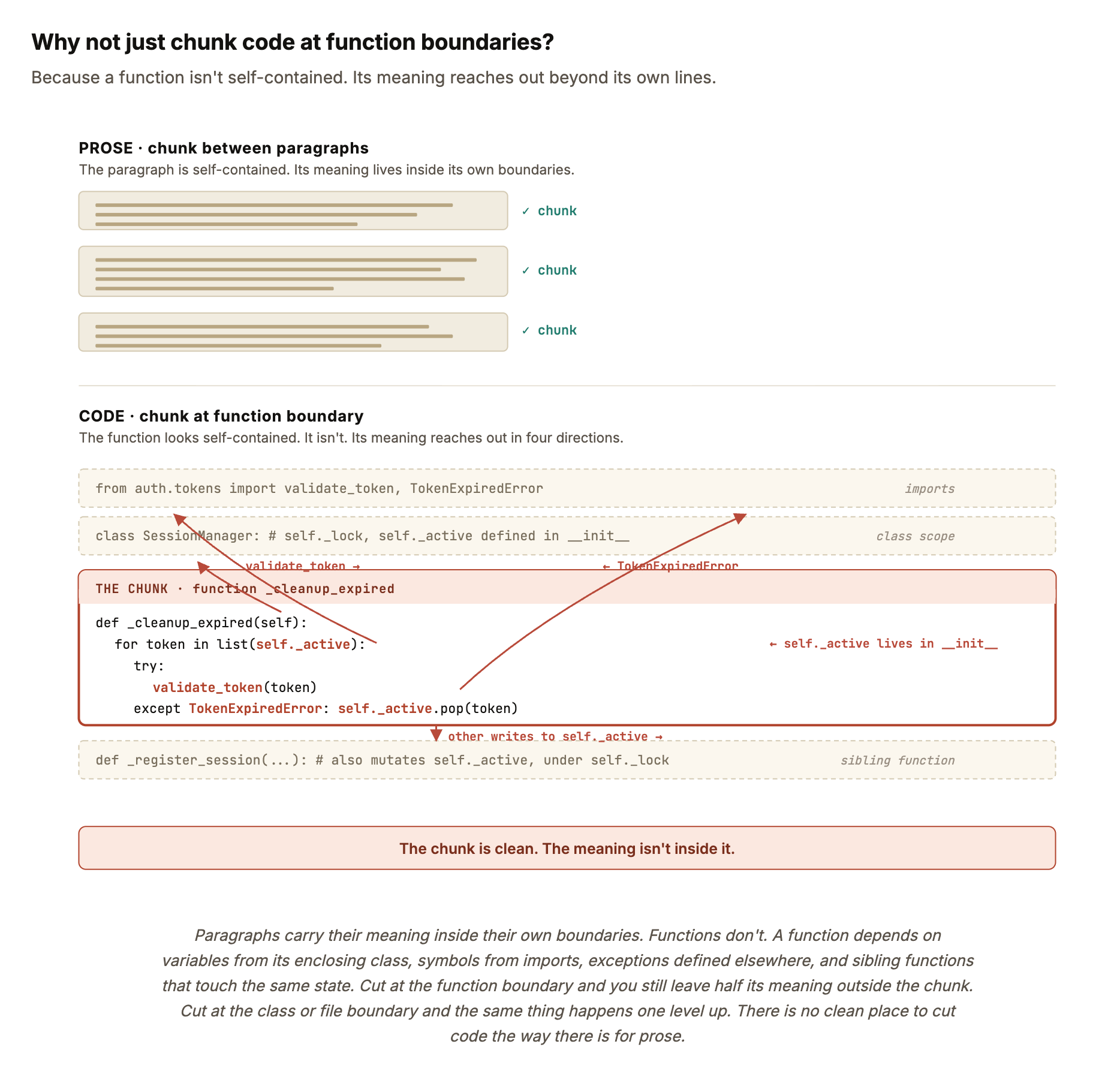
Code isn’t flat. A function is a node. It calls other functions. It lives inside a class, which lives inside a module, which gets imported by other modules. Every line exists inside a nested scope. Every variable belongs to a specific namespace. The shape of code is not an afterthought. The shape is the meaning.
Treat code like prose, chunk it into 512-token slices and embed each slice, and the structure disappears the moment it enters the index. The same blind cutting I wrote about for documents (how retrieval loses meaning when a chunk lands in the wrong place) hits harder here, because cutting inside a function is cutting inside a thought.
This is The Structure Problem. It’s the reason a single retrieval strategy was never going to be enough for code. The questions engineers ask about code come in genuinely different shapes, and each shape needs a different kind of search to answer well
Three Shapes of Question in Code
Once you start looking for them, the shapes are easy to spot.
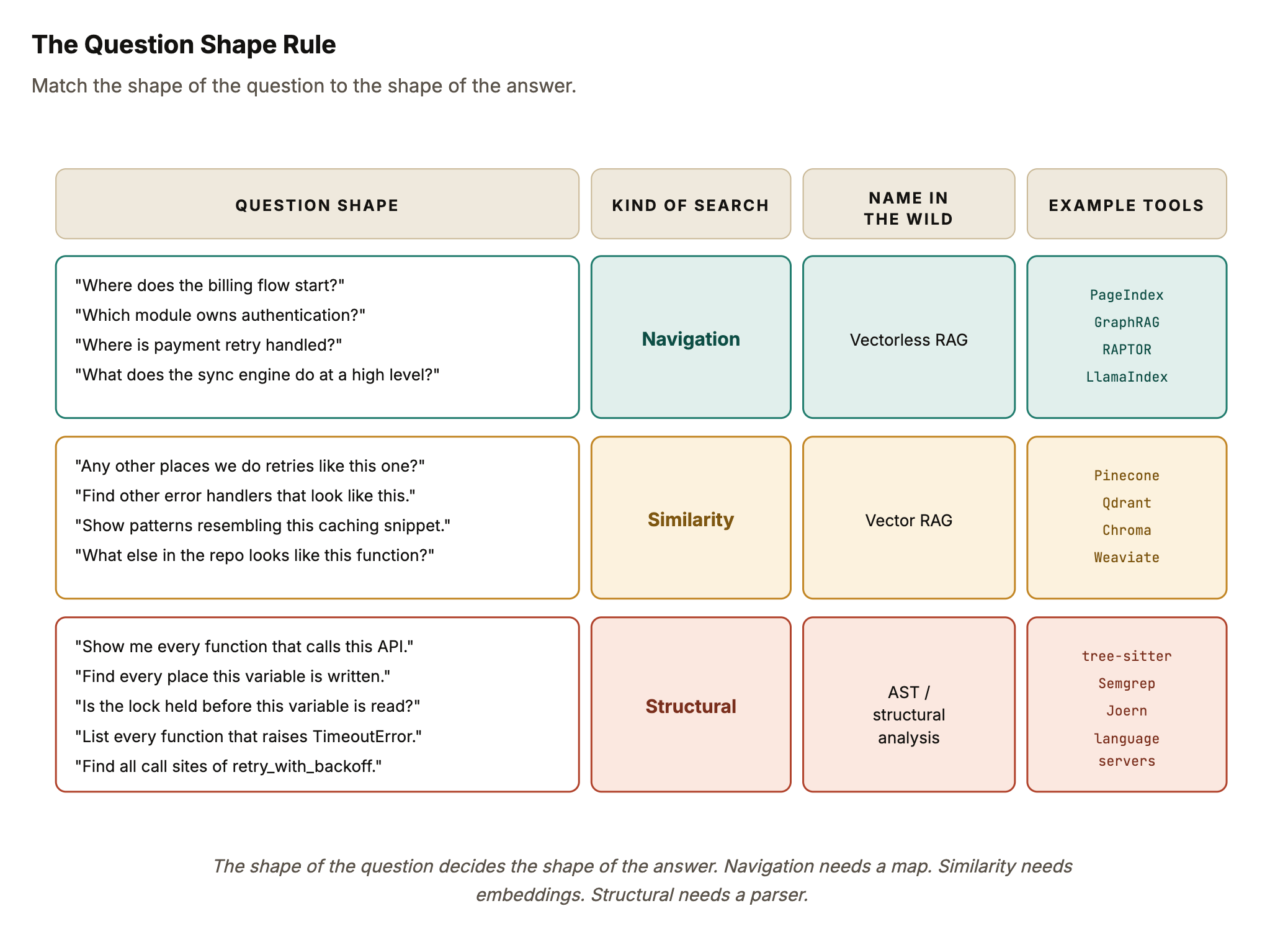
Navigation questions ask where. “Where does the billing flow start?” “Which module owns the caching layer?” “Where is this error handled?” The reader needs a map. They need the system’s architecture, not a specific line of code.
Similarity questions ask what resembles this. “Any other places we do retries like this?” “Have we seen this shape of error-handling before?” The reader is pattern-matching. They want the closest neighbours to something they already have in front of them.
Structural questions ask every place where. “Every function that calls this API.” “Every function that writes to this variable.” “Every place that catches and swallows this exception.” The reader needs completeness and exactness. Missing a single call site can change what they decide.
Each shape naturally pairs with a different kind of search.
The Main Kinds of Search
Navigation pairs with a table-of-contents approach. Instead of chunking the codebase, an LLM reads each file and writes a short natural-language summary of what it does. Those summaries get organised into a hierarchy, roughly like a book’s index. When a navigation question comes in, the LLM traverses that hierarchy and picks the right branch. No embeddings. No similarity score. Just a guided read. This is what writing on retrieval calls Vectorless RAG. (I wrote separately about what actually happens inside the LLM when it makes one of these picks, if you want the attention-level view.)
Similarity pairs with vector search. The classic RAG setup. Each piece of code, or each summary of code, becomes a vector in a high-dimensional space. When a similarity question arrives, the question gets embedded and matched against every stored vector by cosine distance. The closest ones come back. For “find me patterns that look like this,” this is exactly the right tool.
Structural pairs with parsing. Tools like tree-sitter don’t retrieve anything in the RAG sense. They parse source code into an Abstract Syntax Tree, where every function, every call, every exception is a typed node with known children and relationships. Then you query the tree by shape. “Find every call_expression node whose target is retry_with_backoff.” The answer is exhaustive and deterministic. No probability involved.
These three cover most of what engineers actually experience from day to day. There are others worth knowing about — keyword search, graph-based retrieval over call graphs, hybrids that combine similarity and keywords — but the three above are the ones that show up most often when you’re asking questions about a codebase.
They’re also fundamentally different tools. Not three versions of the same idea. Different mathematics, different guarantees, different kinds of answers.
How Coding Assistants Put Them Together
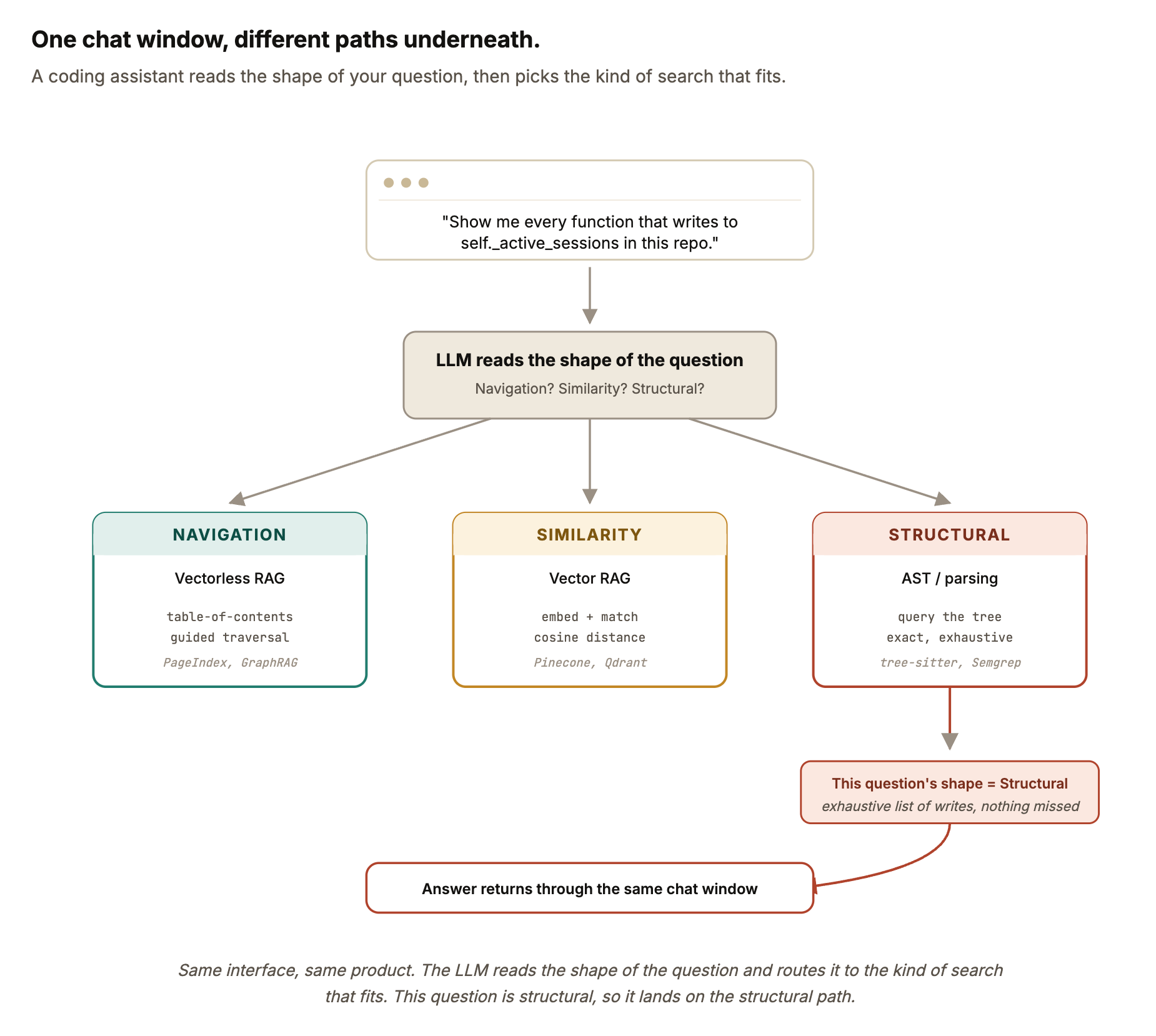
Modern coding assistants don’t commit to one strategy. They orchestrate.
When a question comes in, the LLM sitting at the top reads the shape first. It decides whether this is a navigation question, a similarity question, or a structural one. Sometimes it fires one tool. Sometimes it chains several. A question like “which module handles auth, and what does the retry logic in it look like?” naturally splits into navigation first (find the module), then similarity (find the retry patterns). The user sees one answer. Two different searches produced it.
A useful mental image: the LLM is acting less like a search engine and more like a senior engineer who knows the codebase. When you ask “where is auth?” they open the directory tree. When you ask “find similar retries,” they grep-and-compare. When you ask “every function that writes this variable,” they run a precise structural query or pull up the AST. Same person. Different motions for different questions.
The shape of your question decides the motion.
A Concrete Example: The Missing Lock
Take one of the harder cases — a structural question with real stakes.
Something in production is failing intermittently. Your hunch is a race condition. Two threads reaching for the same shared variable without proper coordination, leaving a window where they collide. To validate that from the code, you need one very specific answer: which functions write to this shared variable without acquiring the lock first?
This is a structural question with a twist. You’re not looking for what’s present in the code. You’re looking for what’s absent. No line of code says “I am missing a lock here.” There is no text to match, no pattern to embed, no nearby word that signals absence. Similarity search finds things that look like other things. It was never built to find the absence of a thing.
A structural tool handles this cleanly, because it can run two exhaustive queries and compare the results:
STRUCTURAL AUDIT (AST parsing)
All writes to self._active_sessions
session_manager.py:58 _cleanup_expired()
session_manager.py:91 _register_session()
session_manager.py:134 _rotate_sessions()
Blocks under `with self._lock:`
session_manager.py:88-95 _register_session()
session_manager.py:130-138 _rotate_sessions()
Cross-reference
✗ _cleanup_expired() writes at line 58, no lock heldOne suspect. Zero guessing. This is what structural parsing is built for. The shape of the question (every write, minus every lock-held write) is exactly the shape the AST can answer.
The same question routed through similarity search would not fail by giving a noisy answer. It would fail by giving a confident answer about something adjacent, because that’s the shape of answer similarity search knows how to produce.
The Question Shape Rule
The takeaway worth keeping.
Pipelines and coding assistants don’t produce off-target answers because the tools underneath are weak. They produce them when a question of one shape gets routed through a search built for another. Navigation sent through a similarity tool. A structural question sent through a navigation tool. The search runs. An answer comes back. It just isn’t the kind of answer the question actually needed.
Coding assistants are genuinely good now. They route most questions well, and a lot of what used to take half an hour now takes thirty seconds. What changes when you know the shapes underneath is not trust in the tool. It’s the precision of your own questions.
You start asking “show me every call site of this function” when you want completeness, instead of “where is this used?” which could route either way. You reach for a structural check when you need certainty and not a confidently-phrased summary. You read what comes back with sharper eyes, because you know what kind of answer it is.
The tools haven’t changed. The way I work with them has.
Thanks for reading. This series has been tracing how retrieval systems actually work from the inside, including the moments where abstractions hide the mechanism. I’ll keep writing in this direction. Subscribe if that’s the kind of thing you want in your inbox.